Security services for instances¶
Entropy to instances¶
We consider entropy to refer to the quality and source of random data that is available to an instance. Cryptographic technologies typically rely heavily on randomness, requiring a high quality pool of entropy to draw from. It is typically hard for a virtual machine to get enough entropy to support these operations, which is referred to as entropy starvation. Entropy starvation can manifest in instances as something seemingly unrelated. For example, slow boot time may be caused by the instance waiting for ssh key generation. Entropy starvation may also motivate users to employ poor quality entropy sources from within the instance, making applications running in the cloud less secure overall.
Fortunately, a cloud architect may address these issues by providing a high quality source of entropy to the cloud instances. This can be done by having enough hardware random number generators (HRNG) in the cloud to support the instances. In this case, “enough” is somewhat domain specific. For everyday operations, a modern HRNG is likely to produce enough entropy to support 50-100 compute nodes. High bandwidth HRNGs, such as the RdRand instruction available with Intel Ivy Bridge and newer processors could potentially handle more nodes. For a given cloud, an architect needs to understand the application requirements to ensure that sufficient entropy is available.
The Virtio RNG is a random number generator that uses
/dev/random as the source of entropy by default, however can be
configured to use a hardware RNG or a tool such as the entropy
gathering daemon (EGD) to provide
a way to fairly and securely distribute entropy through a
distributed system. The Virtio RNG is enabled using the hw_rng
property of the metadata used to create the instance.
Scheduling instances to nodes¶
Before an instance is created, a host for the image
instantiation must be selected. This selection is performed by
the nova-scheduler which determines how to dispatch compute
and volume requests.
The FilterScheduler is the default scheduler for OpenStack
Compute, although other schedulers exist (see the section Scheduling
in the OpenStack Configuration Reference
). This works in collaboration with ‘filter hints’ to decide where an
instance should be started. This process of host selection allows
administrators to fulfill many different security and compliance
requirements. Depending on the cloud deployment type for example, one
could choose to have tenant instances reside on the same hosts whenever
possible if data isolation was a primary concern. Conversely one could
attempt to have instances for a tenant reside on as many different hosts
as possible for availability or fault tolerance reasons.
Filter schedulers fall under four main categories:
- Resource based filters
These filters will create an instance based on the utilizations of the hypervisor host sets and can trigger on free or used properties such as RAM, IO, or CPU utilization.
- Image based filters
This delegates instance creation based on the image used, such as the operating system of the VM or type of image used.
- Environment based filters
This filter will create an instance based on external details such as in a specific IP range, across availability zones, or on the same host as another instance.
- Custom criteria
This filter will delegate instance creation based on user or administrator provided criteria such as trusts or metadata parsing.
Multiple filters can be applied at once, such as the
ServerGroupAffinity filter to ensure an instance is created on a
member of a specific set of hosts and ServerGroupAntiAffinity
filter to ensure that same instance is not created on another specific
set of hosts. These filters should be analyzed carefully to ensure
they do not conflict with each other and result in rules that prevent
the creation of instances.
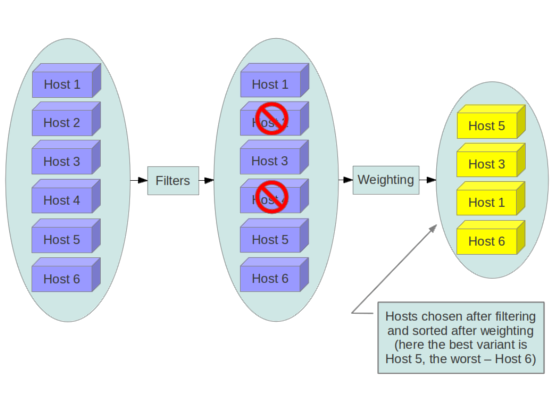
The GroupAffinity and GroupAntiAffinity filters conflict and
should not both be enabled at the same time.
The DiskFilter filter is capable of oversubscribing disk space.
While not normally an issue, this can be a concern on storage devices
that are thinly provisioned, and this filter should be used with
well-tested quotas applied.
We recommend you disable filters that parse things that are provided by users or are able to be manipulated such as metadata.
Trusted images¶
In a cloud environment, users work with either pre-installed images or images they upload themselves. In both cases, users should be able to ensure the image they are utilizing has not been tampered with. The ability to verify images is a fundamental imperative for security. A chain of trust is needed from the source of the image to the destination where it’s used. This can be accomplished by signing images obtained from trusted sources and by verifying the signature prior to use. Various ways to obtain and create verified images will be discussed below, followed by a description of the image signature verification feature.
Image creation process¶
The OpenStack Documentation provides guidance on how to create and upload an image to the Image service. Additionally it is assumed that you have a process by which you install and harden operating systems. Thus, the following items will provide additional guidance on how to ensure your images are transferred securely into OpenStack. There are a variety of options for obtaining images. Each has specific steps that help validate the image’s provenance.
The first option is to obtain boot media from a trusted source.
$ mkdir -p /tmp/download_directorycd /tmp/download_directory
$ wget http://mirror.anl.gov/pub/ubuntu-iso/CDs/precise/ubuntu-12.04.2-server-amd64.iso
$ wget http://mirror.anl.gov/pub/ubuntu-iso/CDs/precise/SHA256SUMS
$ wget http://mirror.anl.gov/pub/ubuntu-iso/CDs/precise/SHA256SUMS.gpg
$ gpg --keyserver hkp://keyserver.ubuntu.com --recv-keys 0xFBB75451
$ gpg --verify SHA256SUMS.gpg SHA256SUMSsha256sum -c SHA256SUMS 2>&1 | grep OK
The second option is to use the OpenStack Virtual Machine Image Guide. In this case, you will want to follow your organizations OS hardening guidelines or those provided by a trusted third-party such as the Linux STIGs.
The final option is to use an automated image builder. The following example uses the Oz image builder. The OpenStack community has recently created a newer tool worth investigating: disk-image-builder. We have not evaluated this tool from a security perspective.
Example of RHEL 6 CCE-26976-1 which will help implement NIST 800-53 Section AC-19(d) in Oz.
<template>
<name>centos64</name>
<os>
<name>RHEL-6</name>
<version>4</version>
<arch>x86_64</arch>
<install type='iso'>
<iso>http://trusted_local_iso_mirror/isos/x86_64/RHEL-6.4-x86_64-bin-DVD1.iso</iso>
</install>
<rootpw>CHANGE THIS TO YOUR ROOT PASSWORD</rootpw>
</os>
<description>RHEL 6.4 x86_64</description>
<repositories>
<repository name='epel-6'>
<url>http://download.fedoraproject.org/pub/epel/6/$basearch</url>
<signed>no</signed>
</repository>
</repositories>
<packages>
<package name='epel-release'/>
<package name='cloud-utils'/>
<package name='cloud-init'/>
</packages>
<commands>
<command name='update'>
yum update
yum clean all
rm -rf /var/log/yum
sed -i '/^HWADDR/d' /etc/sysconfig/network-scripts/ifcfg-eth0
echo -n > /etc/udev/rules.d/70-persistent-net.rules
echo -n > /lib/udev/rules.d/75-persistent-net-generator.rules
chkconfig --level 0123456 autofs off
service autofs stop
</command>
</commands>
</template>
It is recommended to avoid the manual image building process as it is complex and prone to error. Additionally, using an automated system like Oz for image building or a configuration management utility like Ansible or Puppet for post-boot image hardening gives you the ability to produce a consistent image as well as track compliance of your base image to its respective hardening guidelines over time.
If subscribing to a public cloud service, you should check with the cloud provider for an outline of the process used to produce their default images. If the provider allows you to upload your own images, you will want to ensure that you are able to verify that your image was not modified before using it to create an instance. To do this, refer to the following section on Image Signature Verification, or the following paragraph if signatures cannot be used.
Images come from the Image service to the Compute service on a node. This transfer should be protected by running over TLS. Once the image is on the node, it is verified with a basic checksum and then its disk is expanded based on the size of the instance being launched. If, at a later time, the same image is launched with the same instance size on this node, it is launched from the same expanded image. Since this expanded image is not re-verified by default before launching, it is possible that it has undergone tampering. The user would not be aware of tampering, unless a manual inspection of the files is performed in the resulting image.
Image signature verification¶
Several features related to image signing are now available in OpenStack. As of the Mitaka release, the Image service can verify these signed images, and, to provide a full chain of trust, the Compute service has the option to perform image signature verification prior to image boot. Successful signature validation before image boot ensures the signed image hasn’t changed. With this feature enabled, unauthorized modification of images (e.g., modifying the image to include malware or rootkits) can be detected.
Administrators can enable instance signature verification by setting
the verify_glance_signatures flag to True in the
/etc/nova/nova.conf file. When enabled, the Compute service
automatically validates the signed instance when it is retrieved from
the Image service. If this verification fails, the boot won’t occur.
The OpenStack Operations Guide provides guidance on how to create and
upload a signed image, and how to use this feature. For more
information, see Adding Signed Images
in the Operations Guide.
Instance migrations¶
OpenStack and the underlying virtualization layers provide for the live migration of images between OpenStack nodes, allowing you to seamlessly perform rolling upgrades of your OpenStack compute nodes without instance downtime. However, live migrations also carry significant risk. To understand the risks involved, the following are the high-level steps performed during a live migration:
Start instance on destination host
Transfer memory
Stop the guest and sync disks
Transfer state
Start the guest
Live migration risks¶
At various stages of the live migration process the contents of an instances run time memory and disk are transmitted over the network in plain text. Thus there are several risks that need to be addressed when using live migration. The following in-exhaustive list details some of these risks:
Denial of Service (DoS): If something fails during the migration process, the instance could be lost.
Data exposure: Memory or disk transfers must be handled securely.
Data manipulation: If memory or disk transfers are not handled securely, then an attacker could manipulate user data during the migration.
Code injection: If memory or disk transfers are not handled securely, then an attacker could manipulate executables, either on disk or in memory, during the migration.
Live migration mitigations¶
There are several methods to mitigate some of the risk associated with live migrations, the following list details some of these:
Disable live migration
Isolated migration network
Encrypted live migration
Disable live migration¶
At this time, live migration is enabled in OpenStack
by default. Live migrations can be disabled by adding the
following lines to the nova policy.json file:
{
"compute_extension:admin_actions:migrate": "!",
"compute_extension:admin_actions:migrateLive": "!",
}
Migration network¶
As a general practice, live migration traffic should be restricted to the management security domain, see Security boundaries and threats. With live migration traffic, due to its plain text nature and the fact that you are transferring the contents of disk and memory of a running instance, it is recommended you further separate live migration traffic onto a dedicated network. Isolating the traffic to a dedicated network can reduce the risk of exposure.
Encrypted live migration¶
If there is a sufficient business case for keeping live migration enabled, then libvirtd can provide encrypted tunnels for the live migrations. However, this feature is not currently exposed in either the OpenStack Dashboard or nova-client commands, and can only be accessed through manual configuration of libvirtd. The live migration process then changes to the following high-level steps:
Instance data is copied from the hypervisor to libvirtd.
An encrypted tunnel is created between libvirtd processes on both source and destination hosts.
Destination libvirtd host copies the instances back to an underlying hypervisor.
Monitoring, alerting, and reporting¶
As an OpenStack virtual machine is a server image able to be replicated across hosts, best practice in logging applies similarly between physical and virtual hosts. Operating system-level and application-level events should be logged, including access events to hosts and data, user additions and removals, changes in privilege, and others as dictated by the environment. Ideally, you can configure these logs to export to a log aggregator that collects log events, correlates them for analysis, and stores them for reference or further action. One common tool to do this is an ELK stack, or Elasticsearch, Logstash, and Kibana.
These logs should be reviewed at a regular cadence such as a live view by a network operations center (NOC), or if the environment is not large enough to necessitate a NOC, then logs should undergo a regular log review process.
Many times interesting events trigger an alert which is sent to a responder for action. Frequently this alert takes the form of an email with the messages of interest. An interesting event could be a significant failure, or known health indicator of a pending failure. Two common utilities for managing alerts are Nagios and Zabbix.
Updates and patches¶
A hypervisor runs independent virtual machines. This hypervisor can run in an operating system or directly on the hardware (called baremetal). Updates to the hypervisor are not propagated down to the virtual machines. For example, if a deployment is using XenServer and has a set of Debian virtual machines, an update to XenServer will not update anything running on the Debian virtual machines.
Therefore, we recommend that clear ownership of virtual machines be assigned, and that those owners be responsible for the hardening, deployment, and continued functionality of the virtual machines. We also recommend that updates be deployed on a regular schedule. These patches should be tested in an environment as closely resembling production as possible to ensure both stability and resolution of the issue behind the patch.
Firewalls and other host-based security controls¶
Most common operating systems include host-based firewalls for additional security. While we recommend that virtual machines run as few applications as possible (to the point of being single-purpose instances, if possible), all applications running on a virtual machine should be profiled to determine what system resources the application needs access to, the lowest level of privilege required for it to run, and what the expected network traffic is that will be going into and coming from the virtual machine. This expected traffic should be added to the host-based firewall as allowed traffic (or whitelisted), along with any necessary logging and management communication such as SSH or RDP. All other traffic should be explicitly denied in the firewall configuration.
On Linux virtual machines, the application profile above can be used in conjunction with a tool like audit2allow to build an SELinux policy that will further protect sensitive system information on most Linux distributions. SELinux uses a combination of users, policies and security contexts to compartmentalize the resources needed for an application to run, and segmenting it from other system resources that are not needed.
OpenStack provides security groups for both hosts and the network to add defense in depth to the virtual machines in a given project. These are similar to host-based firewalls as they allow or deny incoming traffic based on port, protocol, and address, however security group rules are applied to incoming traffic only, while host-based firewall rules are able to be applied to both incoming and outgoing traffic. It is also possible for host and network security group rules to conflict and deny legitimate traffic. We recommend ensuring that security groups are configured correctly for the networking being used. See Security groups in this guide for more detail.
