Code refactoring for performance improvement¶
https://blueprints.launchpad.net/tacker/+spec/system-performance-management
Problem description¶
Commercial systems, which is one of Tacker’s main target requires high performance software. However, evaluations with simultaneous Lifecycle Management (LCM) operations revealed some issues related to Tacker’s performance. Therefore, further introduction of Tacker to commercial Management and Orchestration (MANO) systems requires performance improvements such as higher concurrency, higher throughput, and shorter turnaround time.
This specification proposes the following code refactoring.
Reduce transactions of getting OpenStack resource (for Tacker v2 API)
Support subscription filter (vnfdId) (for Tacker v1 API)
Refactor the Tacker Output Logs (for Tacker v1/v2 API)
Proposed Change¶
1. Reduce transactions of getting OpenStack resource (for Tacker v2 API)¶
When executing VNF LCM operation
such as Instantiate, Terminate, Scale, and Heal,
current implementation uses "Find stack" API [1]
to check the status of the stack resource.
Since "Find stack" API requires redirection,
it may put heavy load on HEAT.
This specification proposes using "Show stack details" API
instead of "Find stack" API.
Since "Show stack details" API does not need the redirection,
it decreases the number of transaction between Tacker and HEAT from two to one.
Find stack (with Redirection)
[GET] /v1/{tenant_id}/stacks/{stack_identity}Note
“stack_identity” is the UUID or the name of a stack. Since the http-related library (Python library) automatically sends the redirection request containing the
"stack_id"parameter, the"stack_id"is not recognized by the Tacker-conductor at the sending stage of the redirection.Show stack details (without Redirection)
[GET] /v1/{tenant_id}/stacks/{stack_name}/{stack_id}
In the current implementation, "stack_id"
is not stored in Tacker DB
because there is no corresponding data model in the ETSI NFV standard
[2], [3].
To use "Show stack details" directly,
"stack_id" needs to be handled by Tacker.
Following shows two options for handling the "stack_id".
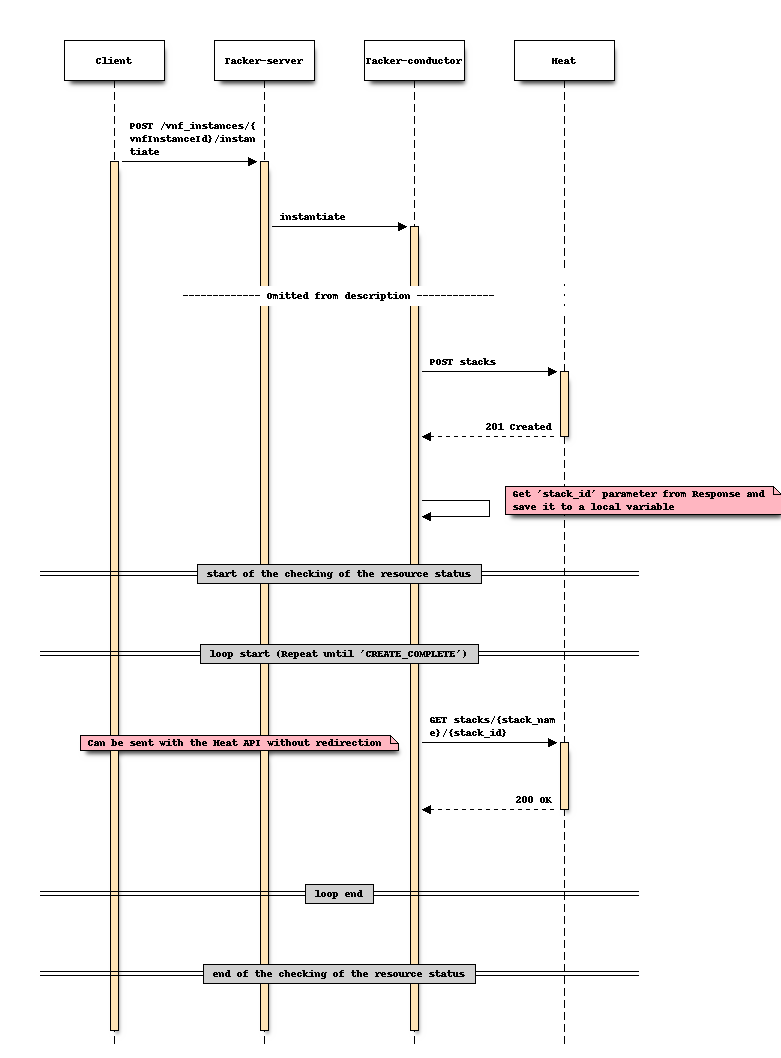
Option 1: Use the “stack_id” obtained in each LCM execution¶
This option is to directly invoke "Show stack details"
by passing "stack_id" obtained when the process of each LCM operation.
“stack_id” can be obtained at the following steps.
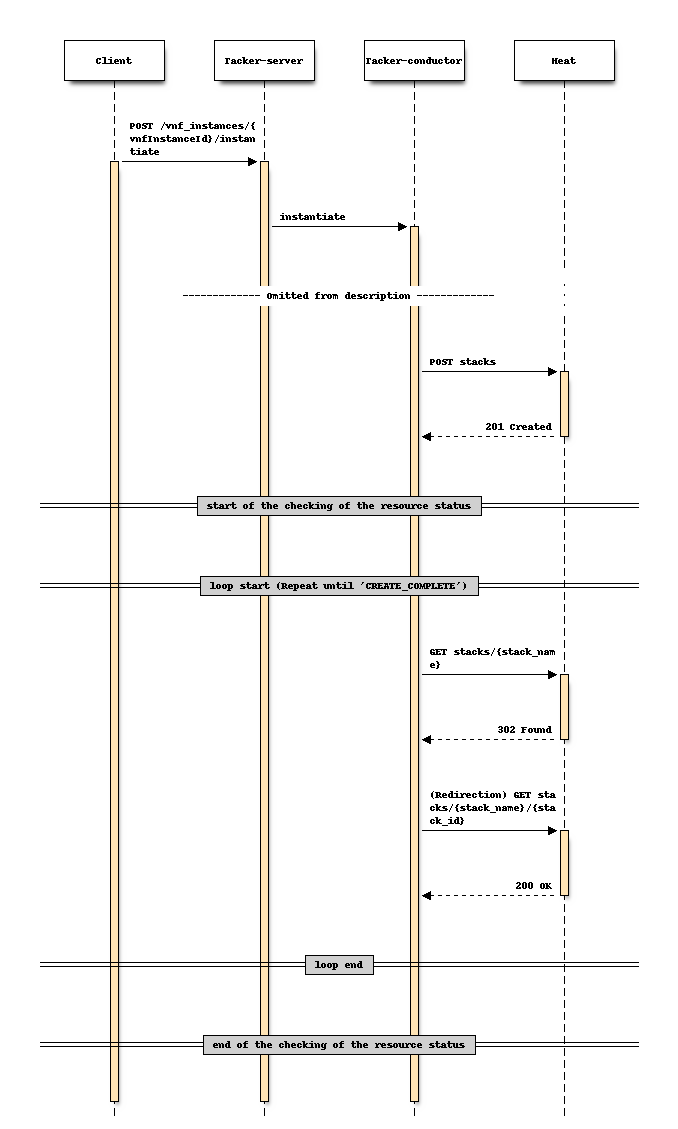
Instantiate:When using the “Create stack” API.
Terminate/Scale/Heal:When using the “Find stack” API for the first time.
For Instantiate
Sequence before changing (Instantiate)
Sequence after changing (Instantiate)
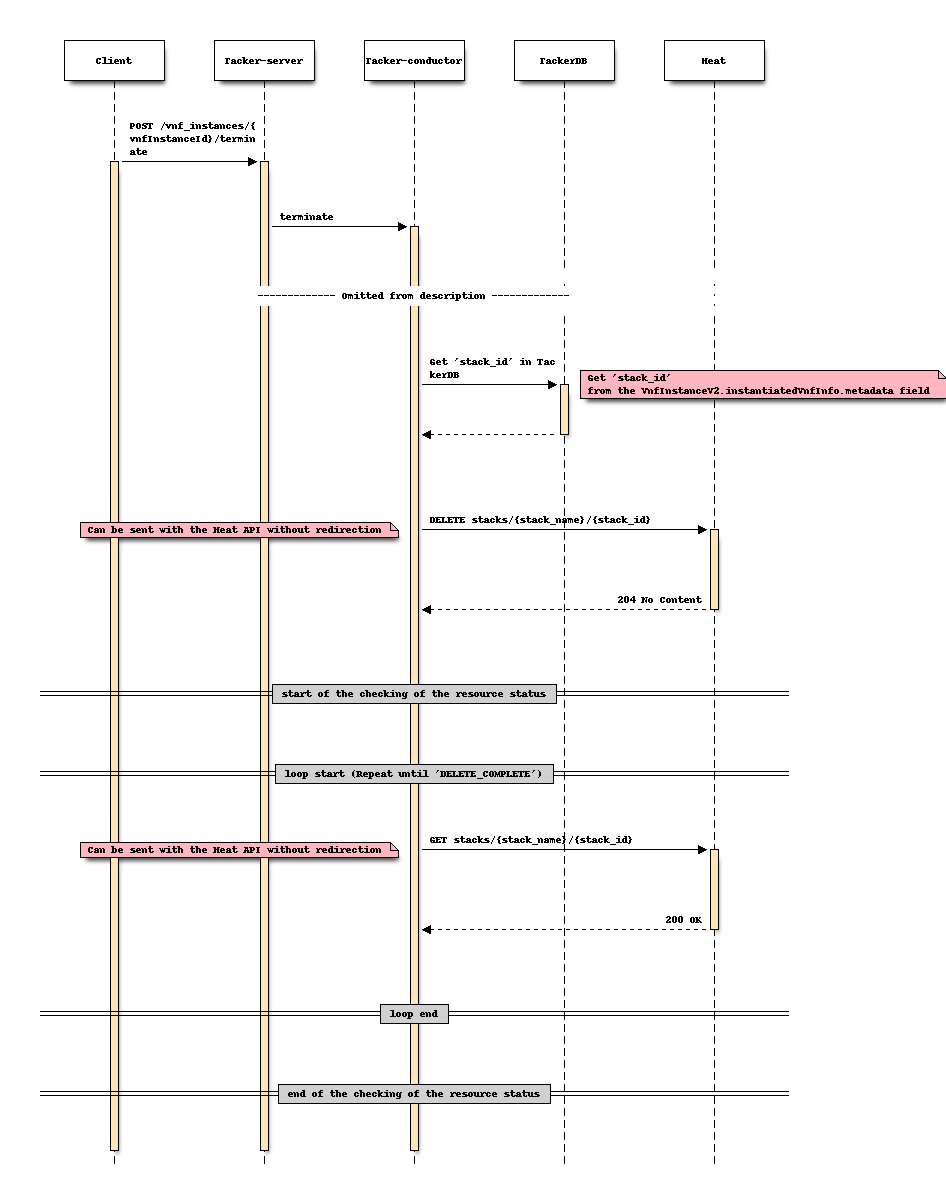
For Terminate
Sequence before changing (Terminate)
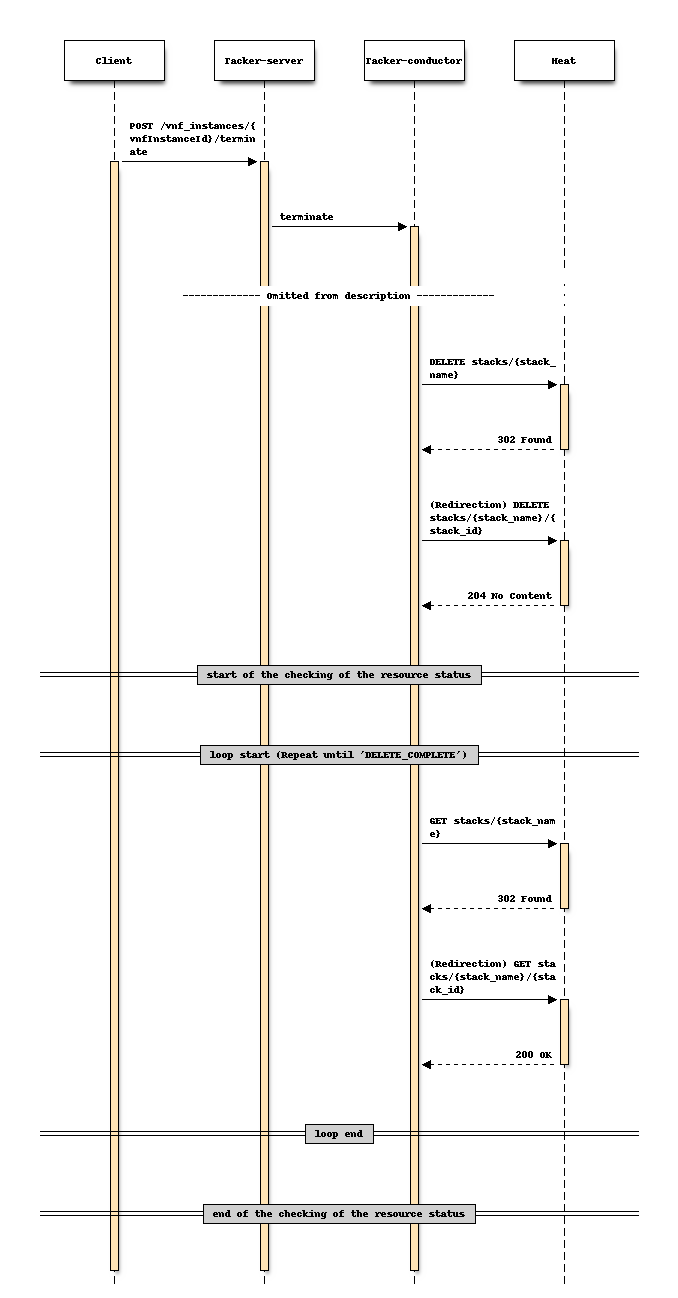
Sequence after changing (Terminate)
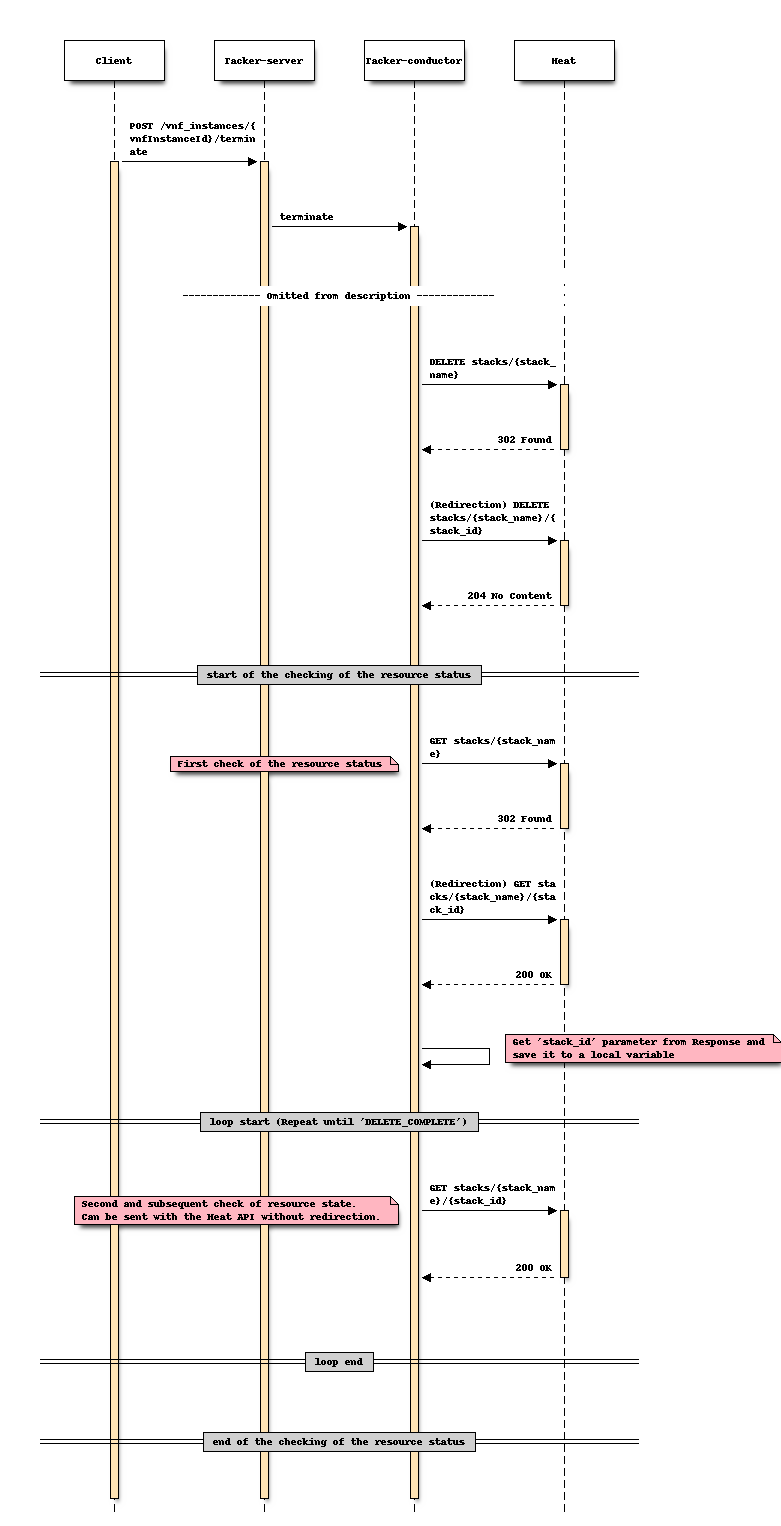
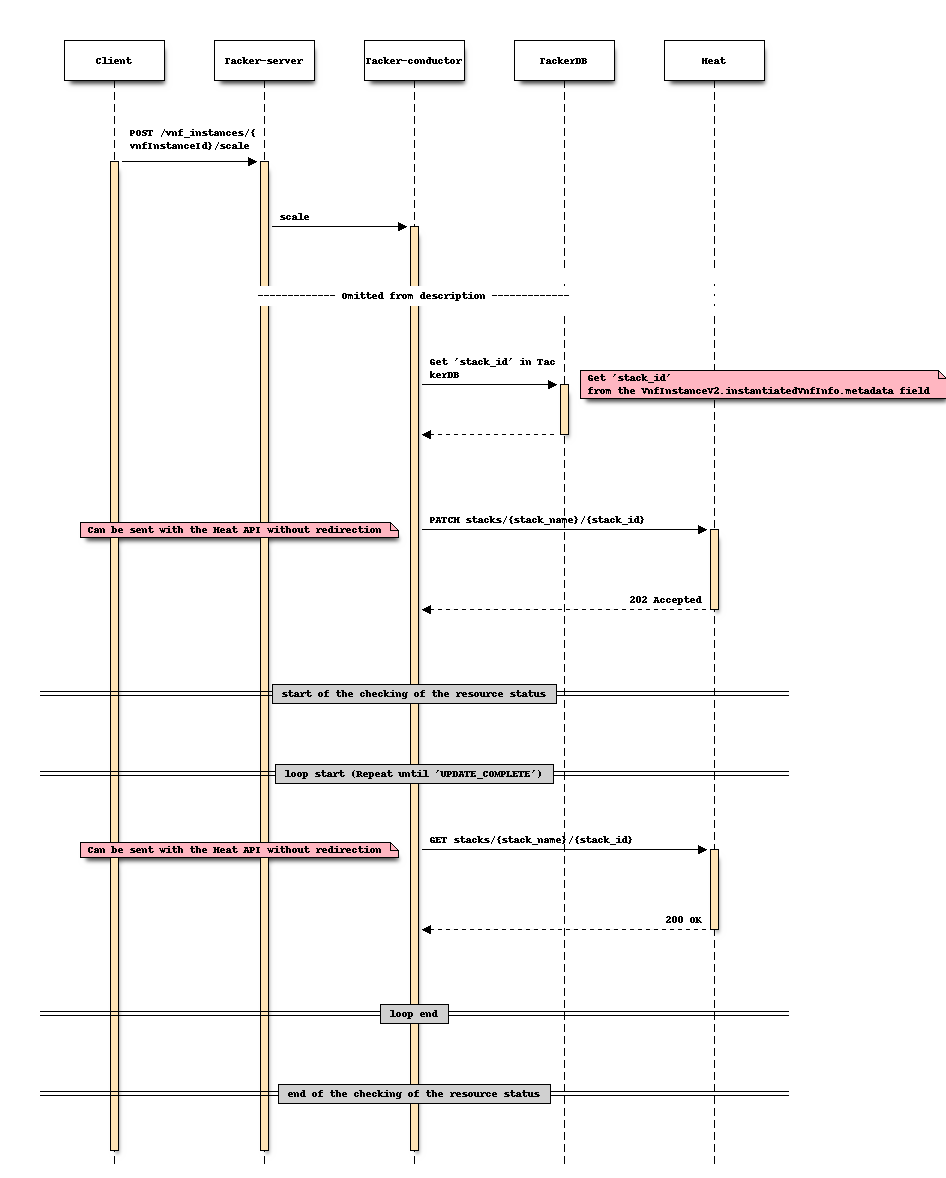
For Scale
Sequence before changing (Scale)
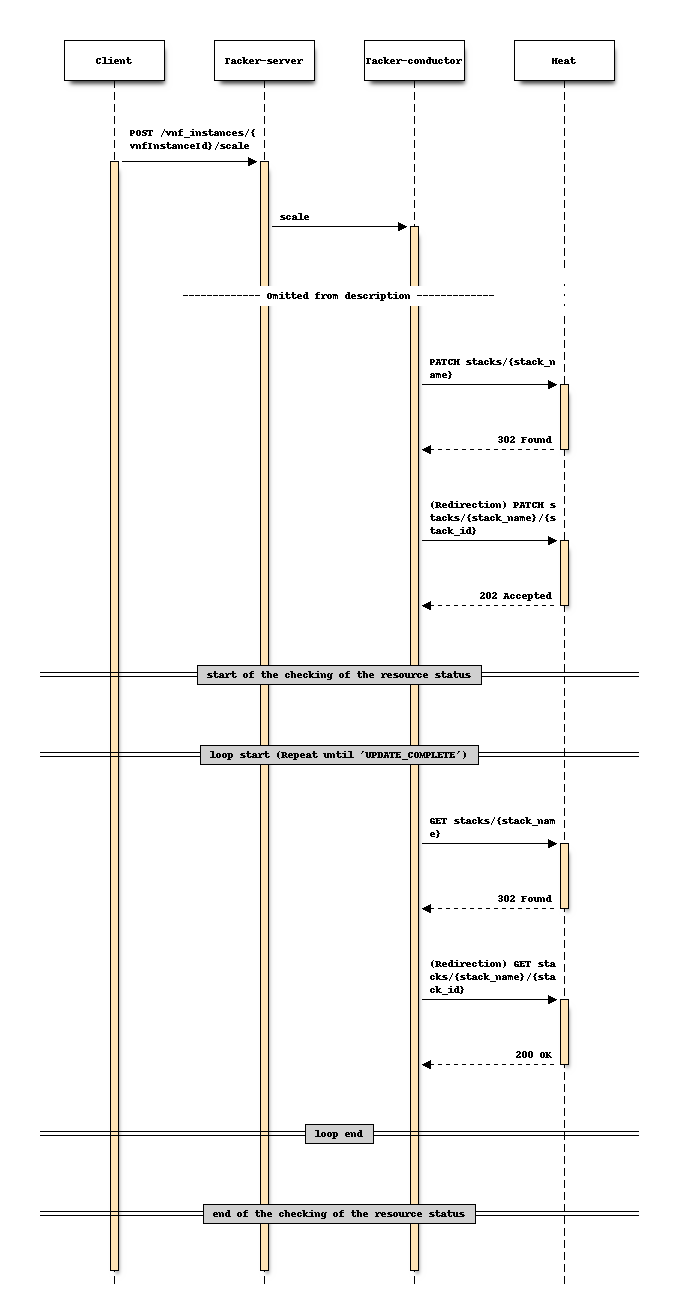
Sequence after changing (Scale)
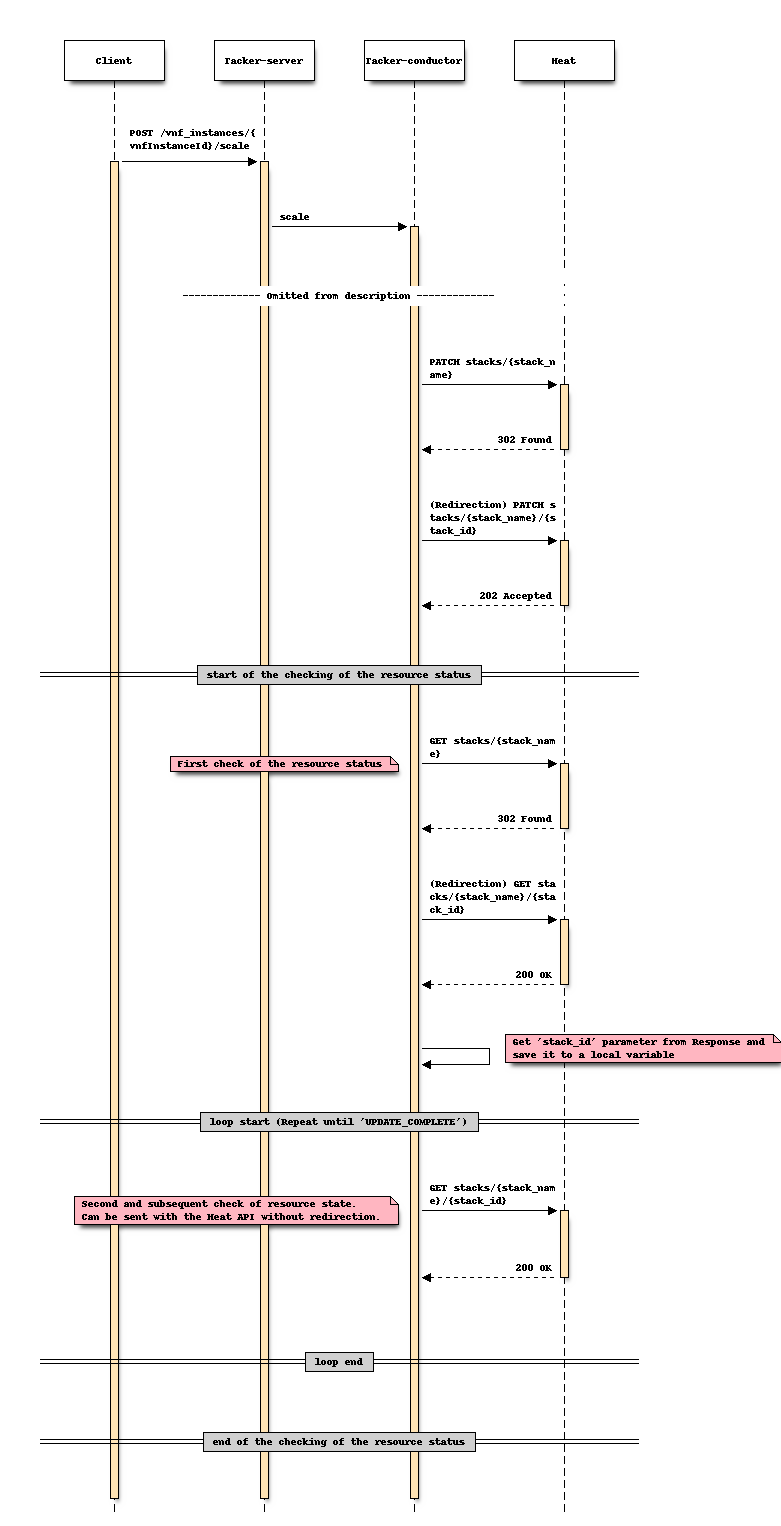
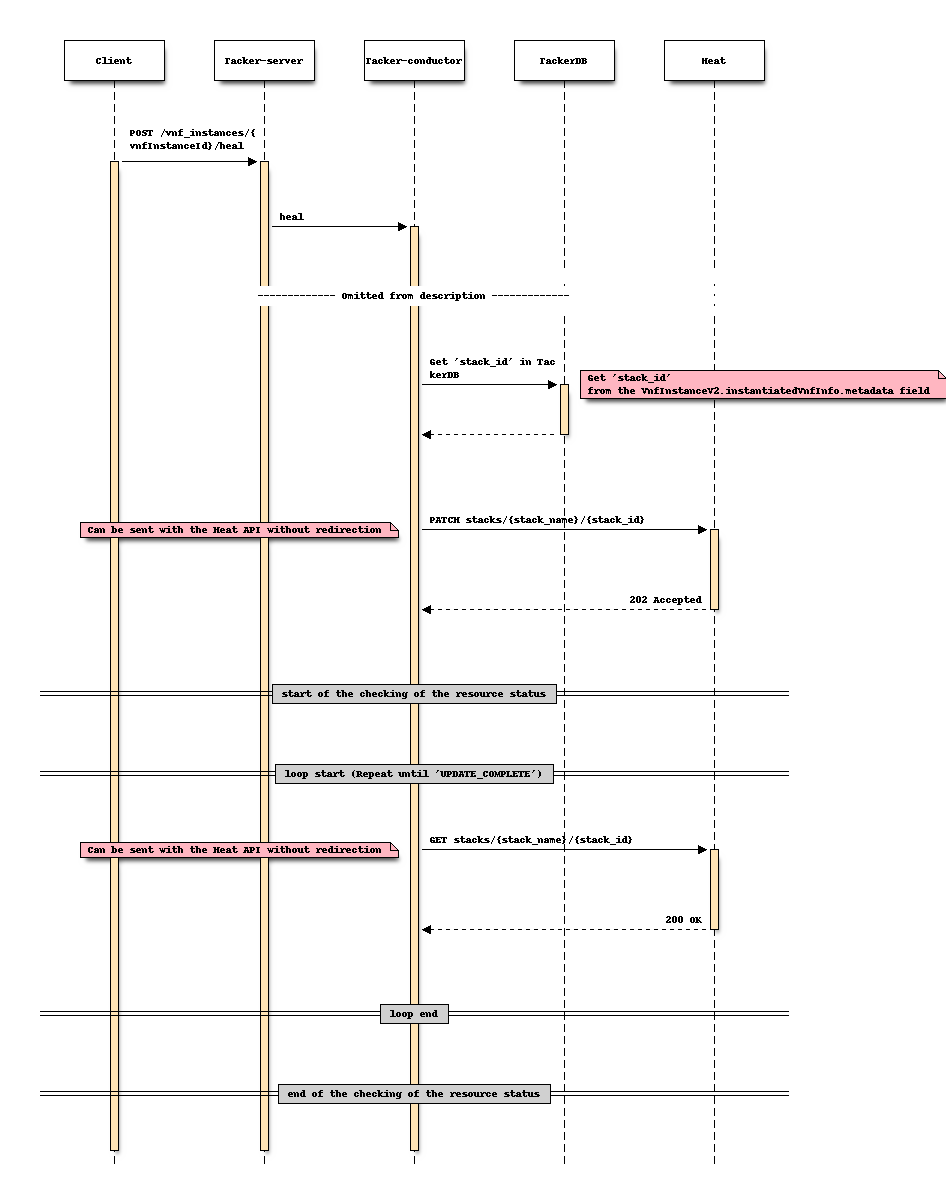
For Heal
Sequence before changing (Heal)
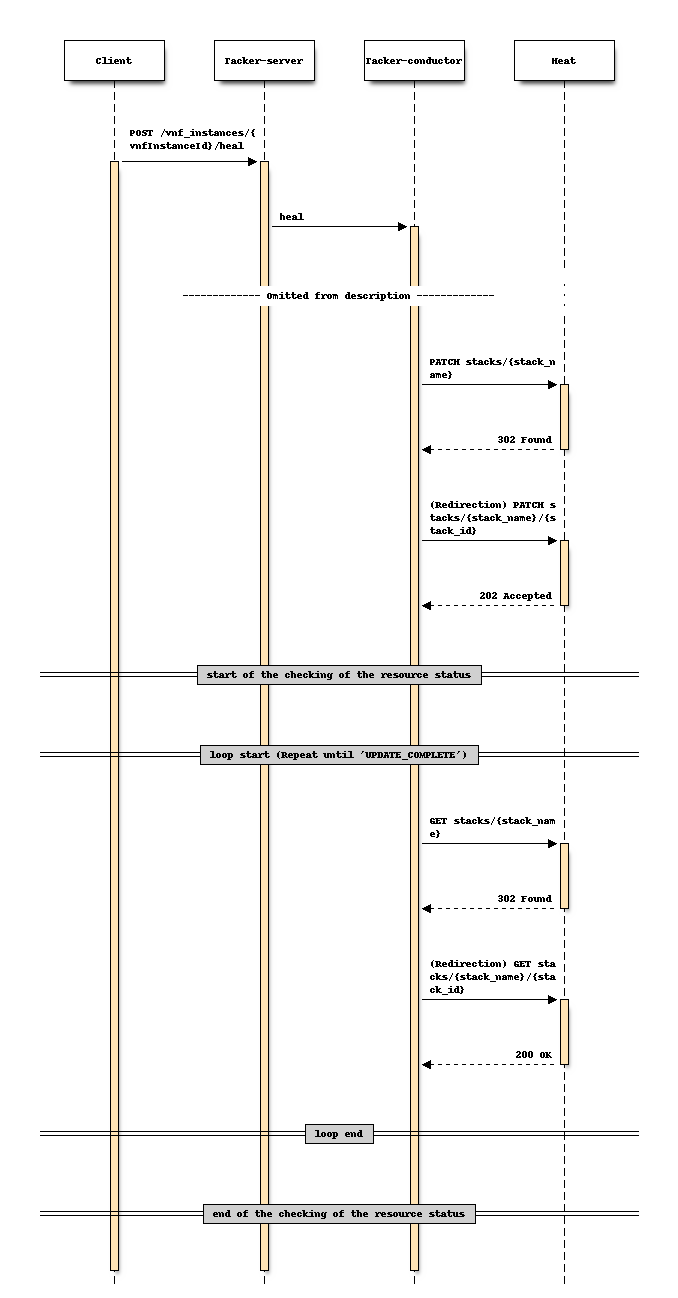
Sequence after changing (Heal)
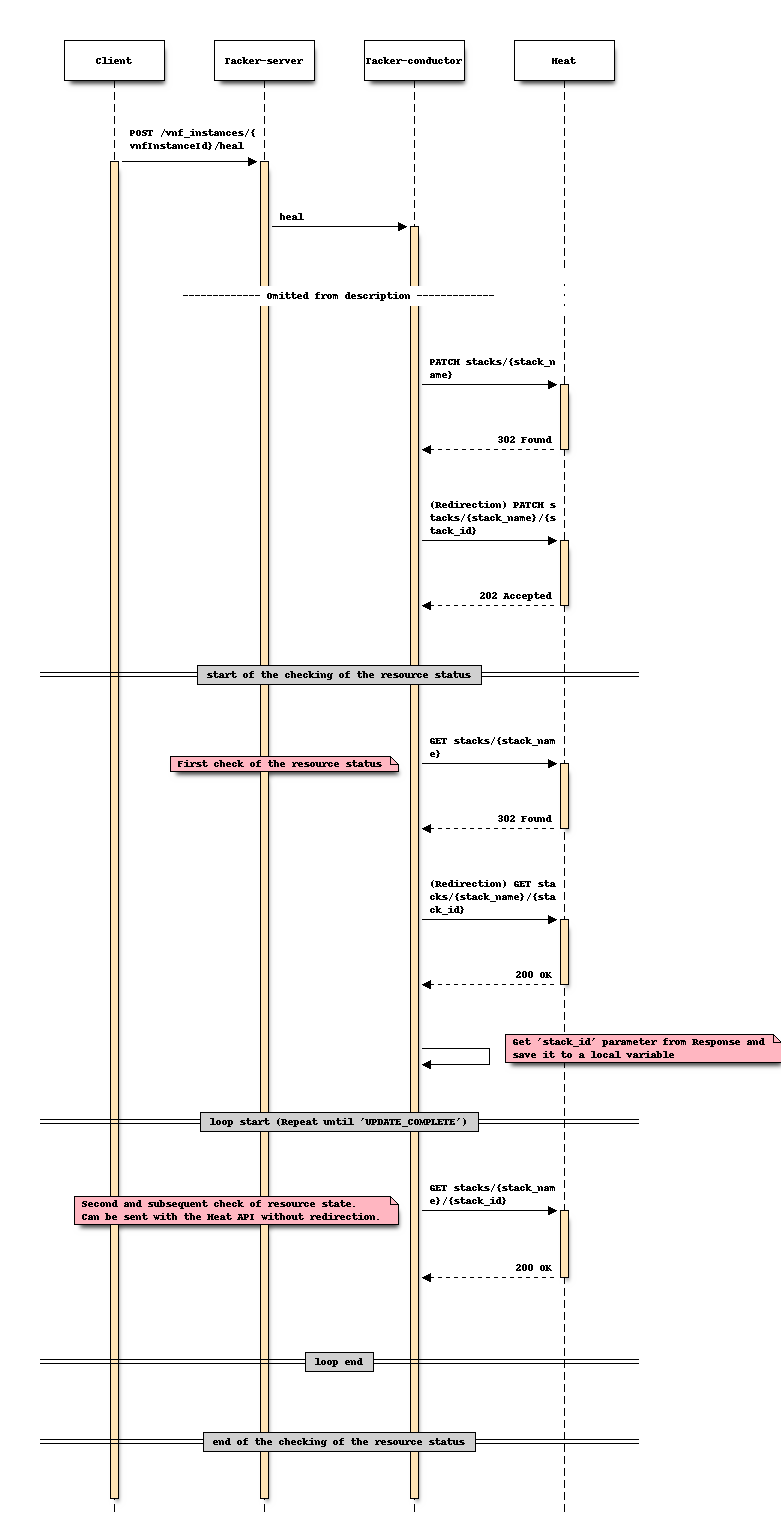
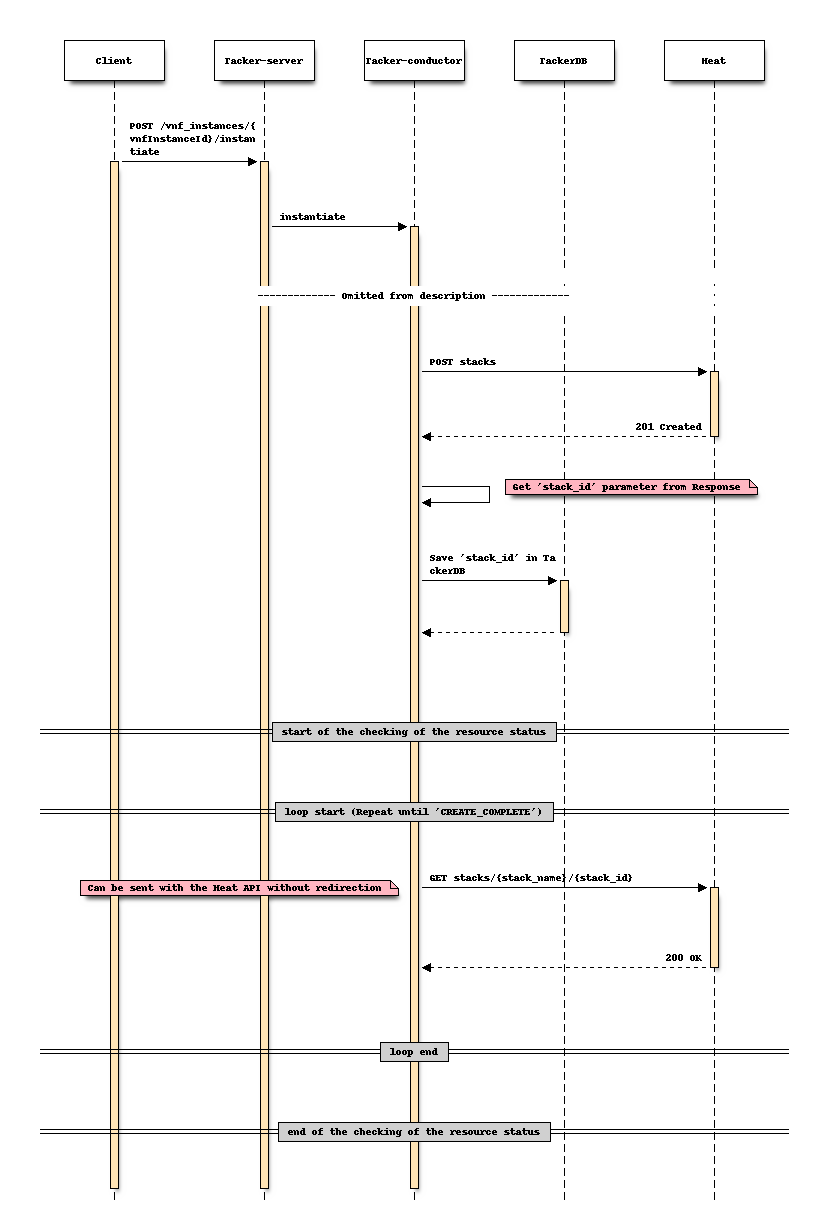
Option 2: Store “stack_id” in Tacker DB obtained during the Instantiate process¶
This option is to directly invoke "Show stack details"
by using the "stack_id" stored in Tacker DB
obtained during the Instantiate process when executing Create stack.
It would be appropriate to store the "stack_id"
in the VnfInstanceV2.instantiatedVnfInfo.metadata field.
Sequence before changing (Instantiate, Terminate, Scale, Heal)
Same as
Sequence before changinginOption 1.Sequence after changing (Instantiate)
Sequence after changing (Terminate)
Sequence after changing (Scale)
Sequence after changing (Heal)
- Similar performance improvements can be made during other LCM operations.For example, in the “Rollback” process for Instantiate, the “DELETE stack” can use the “stack_id” as described above to improve performance.
Note
For Options 1 and 2, If the “stack_id” is lost unintentionally, the redirection API is used to retrieve the information again.
Note
Advantages and disadvantages of option 1 and 2 are shown below.
Option 1 :
Advantages: there is no impact on the existing Tacker DB.
Disadvantages: frequency of the HEAT request is higher than Option 2.
Option 2 :
Advantages: the number of HEAT requests is less than Option 1.
Disadvantages: Tacker DB must store the data not defined in NFV standard.
2. Support subscription filter (vnfdId) (for Tacker v1 API)¶
The Tacker v1 API has not supported Subscription filter of vnfdId. It causes large log sizes and communication delays by sending Notifications on all subscriptions registered in Tacker DB.
To resolve the issues, this specification proposes supporting Subscription filter of vnfdId.
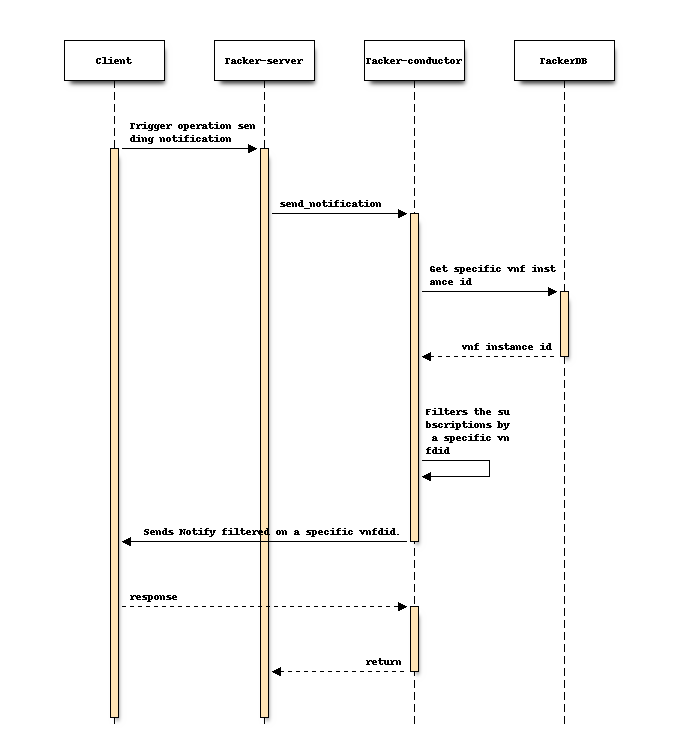
Design of Subscription filter of vnfdId¶
This proposal enables Tacker v1 API to send Notifications related to specific vnfdId.
The following shows the flow of Notify communication processing with the Subscription filter by vnfdId.
3. Refactor the Tacker Output Logs (for Tacker v1/v2 API)¶
This specification proposes the refactoring of the current Tacker output log to resolve the following issues.
The info level logs in a double loop¶
The current implementation has info level logs in a double loop, which results in large output logs and performance impact.
Specific examples is shown below.
def send_notification(self, context, notification):
:
for line in vnf_lcm_subscriptions:
notification['subscriptionId'] = line.id
if (notification.get('notificationType') ==
'VnfLcmOperationOccurrenceNotification'):
notification['_links']['subscription'] = {}
notification['_links']['subscription']['href'] = \
CONF.vnf_lcm.endpoint_url + \
"/vnflcm/v1/subscriptions/" + line.id
else:
notification['links']['subscription'] = {}
notification['links']['subscription']['href'] = \
CONF.vnf_lcm.endpoint_url + \
"/vnflcm/v1/subscriptions/" + line.id
notification['timeStamp'] = datetime.datetime.utcnow(
).isoformat()
try:
self.__set_auth_subscription(line)
for num in range(CONF.vnf_lcm.retry_num):
try:
LOG.info("send notify[%s]" %
json.dumps(notification))
auth_client = auth.auth_manager.get_auth_client(
notification['subscriptionId'])]
Inappropriate log level settings¶
Some implementations of Tacker show the cause of the error at the debug and info levels, making it difficult to analyze the cause. Tacker’s output log level needs to be adjusted to solve this problem.
Specific examples are shown below.
The log shows the cause of the error, but it is difficult to analyze it because the log is specified as info level. This log should be specified as error level.
def _get_vnfd_id(context, id): try: vnf_package_vnfd = \ api.model_query(context, models.VnfPackageVnfd).\ filter_by(package_uuid=id).first() except Exception: LOG.info("select vnf_package_vnfd failed") if vnf_package_vnfd: return vnf_package_vnfd.vnfd_id else: return None
The log is necessary for analysis, but log dict is not required. Therefore, this log should be specified as debug level.
def create_vdu_image_dict(grant_info): """Create a dict containing information about VDU's image. :param grant_info: dict(Grant information format) :return: dict(VDU name, Glance-image uuid) """ vdu_image_dict = {} for vdu_name, resources in grant_info.items(): for vnf_resource in resources: vdu_image_dict[vdu_name] = vnf_resource.resource_identifier LOG.info('vdu_image_dict: %s', vdu_image_dict) return vdu_image_dict
Indicators of log levels¶
Indicators of log levels to output are shown below.
Log Level |
Description |
|---|---|
debug |
Detailed information about system activity. |
info |
Generally useful information to log (service start/stop, configuration assumptions, etc). |
warning |
Incorrect use of the API, near error, etc. any unexpected problem that is not necessarily abnormal but is not normal at runtime. |
error |
Unexpected runtime error or cause of error. |
critical |
Fatal error information. Information that should be addressed if it occurs. |
Note
Appropriate logging levels vary from case to case. Developers are required to specify appropriate logging levels for the case with reference to the two examples in this specification, similar software, and so on.
Data model impact¶
Modify below tables in Tacker database. The corresponding schemas are detailed below:
Option 2 of “Reduce transactions of getting OpenStack resource”
VnfInstanceV2::Add ‘stack_id’ to instantiatedVnfInfo.metadata in json format. The following is the sample data format.
"instantiatedVnfInfo" : { "metadata": { "stack_id": "cb9d8959-ab17-4270-a4c9-257d267ca9f1" } }
REST API impact¶
None
Security impact¶
None
Notification impact¶
None
Other end user impact¶
None
Performance impact¶
Reduce transactions of getting OpenStack resource (for Tacker v2 API)
It reduces the number of HEAT request, which improves performance when running LCM concurrently.
Support subscription filter (vnfdId) (for Tacker v1 API)
It reduces Notifications to user-specified ones, which improves the performance.
Refactor the Log Levels of Tacker Output Logs (for Tacker v1/v2 API)
Removing the info level logs in a double loop will prevent log bloat and suppress performance degradation under heavy load.
Other developer impact¶
None
Developer impact¶
Developers will be able to use appropriate log levels to prevent log bloat and analyze the cause of errors.
Implementation¶
Assignee(s)¶
- Primary assignee:
Hirofumi Noguchi<hirofumi.noguchi.rs@hco.ntt.co.jp>
- Other contributors:
Ayumu Ueha<ueha.ayumu@fujitsu.com>
Yoshiyuki Katada<katada.yoshiyuk@fujitsu.com>
Yusuke Niimi<niimi.yusuke@fujitsu.com>
Work Items¶
“Tacker-conductor” will be modified to implement the following features.
Reduce transactions of getting OpenStack resource (for Tacker v2 API)
Handle “stack_id”.
Change HEAT API usage.
“Tacker-server” will be modified to implement the following features.
Add subscription filter (vnfdId) in Tacker v1 API
Fix the log output of the Tacker implementation to the appropriate log level.
Add new unit and functional tests.
Dependencies¶
Instantiate/Terminate/Scale/Heal operation
Depends on HEAT API “Find stack” [1].
Testing¶
Unit and functional tests will be added to cover cases required in the specification.
Documentation Impact¶
None
