Standard Configuration¶
A configuration designed for scalable and highly available setups.
Note
With Rook, the storage function can be distributed over controllers and/or workers in this configuration.
See Deployment Configuration Terminology for a description of common deployment configuration terminology, including definitions of different node types and network types.
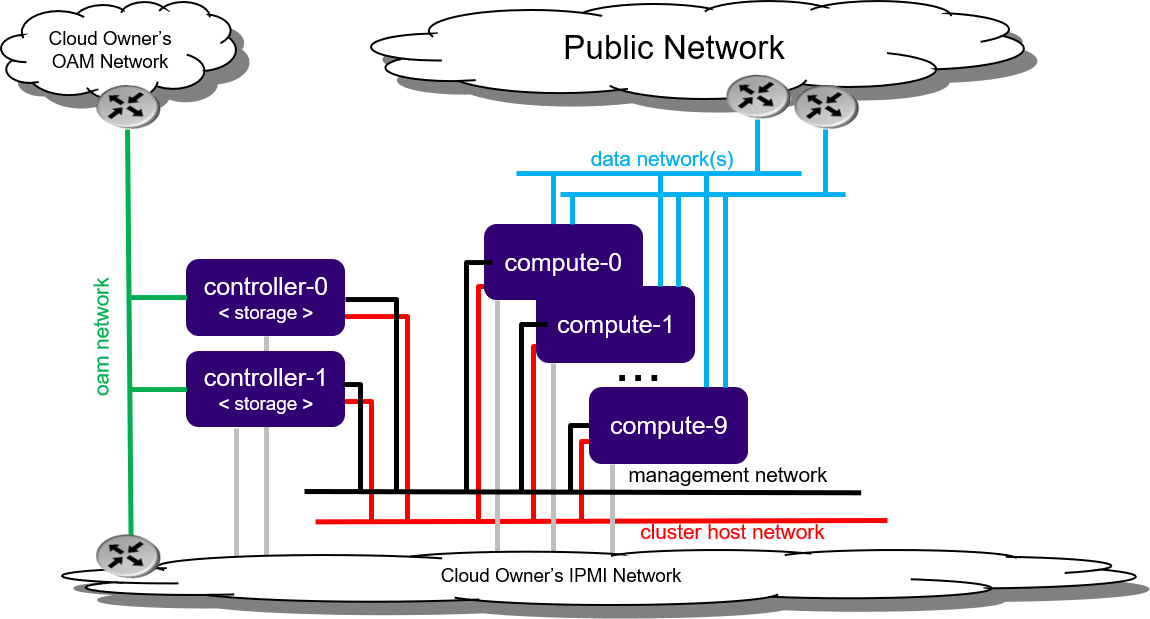
Architecture:
Includes 2 controller nodes, up to 8 storage nodes, and up to 100 worker nodes.
Typical Deployment:
Ideal for large-scale, high-performance environments.
Suitable for environments requiring flexible resource allocation and modular scaling.
Storage Options:
A local, internal Rook-Ceph cluster deployed across controller or worker nodes using either the Controller, Dedicated, or Open Rook deployment model.
Controller Model (default):
For a small-scale storage solution.
OSDs are placed only on controller nodes.
Replication factor is configurable up to size 3 for Standard controller deployments as data Replication is between controller hosts.
Dedicated Model:
OSDs are placed only on a subset of worker nodes that are fully dedicated to storage, not to hosting containerized applications.
Replication factor configurable up to size 3.
Open Model:
No restrictions on OSD placement.
Typically, all or most worker nodes host containerized applications and participate in the local storage function, with one or more disks used as Ceph OSDs.
The replication factor has no limitations.
External storage backends can be configured as an alternative or in addition to the local Rook-managed Ceph cluster. Supported external backends include, for example:
External NetApp Trident backend
External Dell Storage Array backend
Redundancy:
HA controller services run across the two controller nodes in Active/Standby mode.
The Rook-managed Ceph Cluster provides HA through replication in its deployment models. However, for AIO-SX deployments, an HA Ceph monitor configuration is not possible because there is only a single host. HA for Ceph data is only possible if multiple OSDs are configured on that host.
In the event of an overall controller node failure, all controller HA services become active on the remaining healthy controller node, and the above-mentioned Rook-managed Ceph replication protects the Kubernetes PVCs.
In the event of a worker node failure, hosted application containers on the failed worker node are recovered on one or more remaining healthy worker nodes.
Network link redundancy can be improved by deploying redundant Top-of-Rack (ToR) switches. Each link in a link aggregate is connected to a different switch, ensuring connectivity if one switch fails. For more information, see Redundant Top-of-Rack Switch Deployment Considerations .
